AWS Certified Machine Learning Engineer - Associate MLA-C01
Case Study -
A company is building a web-based AI application by using Amazon SageMaker. The application will provide the following capabilities and
features: ML experimentation, training, a central model registry, model deployment, and model monitoring.
The application must ensure secure and isolated use of training data during the ML lifecycle. The training data is stored in Amazon S3.
The company needs to use the central model registry to manage different versions of models in the application.
Which action will meet this requirement with the LEAST operational overhead?
Create a separate Amazon Elastic Container Registry (Amazon ECR) repository for each model.
Use Amazon Elastic Container Registry (Amazon ECR) and unique tags for each model version.
Use the SageMaker Model Registry and model groups to catalog the models. Most Voted
Use the SageMaker Model Registry and unique tags for each model version.
Case Study -
A company is building a web-based AI application by using Amazon SageMaker. The application will provide the following capabilities and
features: ML experimentation, training, a central model registry, model deployment, and model monitoring.
The application must ensure secure and isolated use of training data during the ML lifecycle. The training data is stored in Amazon S3.
The company is experimenting with consecutive training jobs.
How can the company MINIMIZE infrastructure startup times for these jobs?
Use Managed Spot Training.
Use SageMaker managed warm pools. Most Voted
Use SageMaker Training Compiler.
Use the SageMaker distributed data parallelism (SMDDP) library.
Case Study -
A company is building a web-based AI application by using Amazon SageMaker. The application will provide the following capabilities and
features: ML experimentation, training, a central model registry, model deployment, and model monitoring.
The application must ensure secure and isolated use of training data during the ML lifecycle. The training data is stored in Amazon S3.
The company must implement a manual approval-based workflow to ensure that only approved models can be deployed to production endpoints.
Which solution will meet this requirement?
Use SageMaker Experiments to facilitate the approval process during model registration.
Use SageMaker ML Lineage Tracking on the central model registry. Create tracking entities for the approval process.
Use SageMaker Model Monitor to evaluate the performance of the model and to manage the approval.
Use SageMaker Pipelines. When a model version is registered, use the AWS SDK to change the approval status to "Approved." Most Voted
Case Study -
A company is building a web-based AI application by using Amazon SageMaker. The application will provide the following capabilities and
features: ML experimentation, training, a central model registry, model deployment, and model monitoring.
The application must ensure secure and isolated use of training data during the ML lifecycle. The training data is stored in Amazon S3.
The company needs to run an on-demand workflow to monitor bias drift for models that are deployed to real-time endpoints from the application.
Which action will meet this requirement?
Configure the application to invoke an AWS Lambda function that runs a SageMaker Clarify job. Most Voted
Invoke an AWS Lambda function to pull the sagemaker-model-monitor-analyzer built-in SageMaker image.
Use AWS Glue Data Quality to monitor bias.
Use SageMaker notebooks to compare the bias.
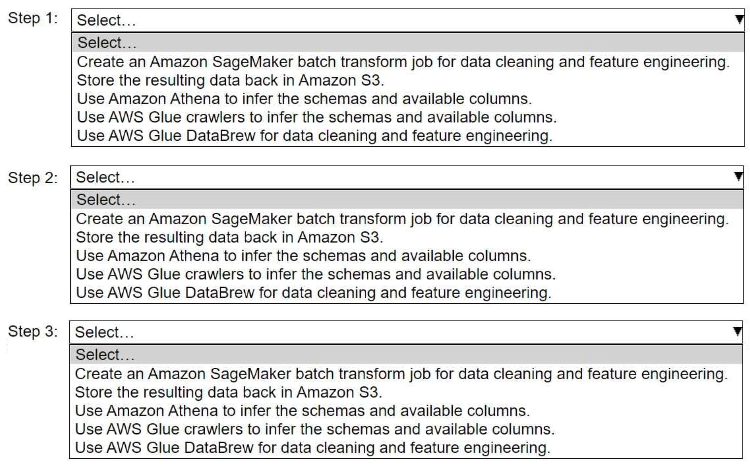
HOTSPOT -
A company stores historical data in .csv files in Amazon S3. Only some of the rows and columns in the .csv files are populated. The columns are
not labeled. An ML engineer needs to prepare and store the data so that the company can use the data to train ML models.
Select and order the correct steps from the following list to perform this task. Each step should be selected one time or not at all. (Select and
order three.)
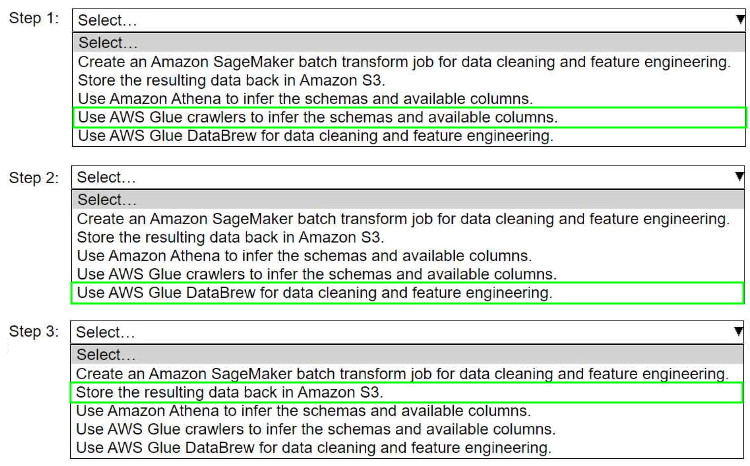
• Create an Amazon SageMaker batch transform job for data cleaning and feature engineering.
• Store the resulting data back in Amazon S3.
• Use Amazon Athena to infer the schemas and available columns.
• Use AWS Glue crawlers to infer the schemas and available columns.
• Use AWS Glue DataBrew for data cleaning and feature engineering.
Correct Answer:
Unlock All Questions
You are viewing the free preview. Purchase a plan to access all questions, answers, and detailed explanations.